排序算法之桶排序
本文共 1627 字,大约阅读时间需要 5 分钟。
桶排序
桶排序的基本思想就是待排序的数据分别放入不同的桶中,这些桶之间其实是有序的。然后在这些桶中将分在里面的数据进行排序。最终就完成了整个序列的排序。
假设将一个均匀分布在区间[0,200)的一些待排序的序列,分成20个桶中。每个桶的大小都是10。分别存数据[0, 9), [10, 19), [20, 29) …. [190, 199),将待排序数组中的数据分别存进这些桶中,然后分别对桶中的元素进行排序,这样就完成了排序。 比如有数据{32, 43, 1, 65, 43, 57, 83, 93, 73, 22, 28, 53},将这些数据在区间[0, 100)中,将这些数据分进十个桶中,然后在这些桶中对其中的数据进行排序。如下图所示: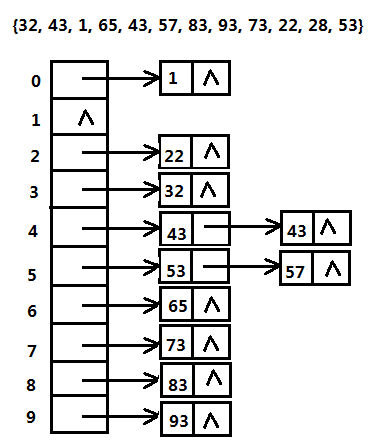 其实桶排序最终构建的结构是一个散列表。
其实桶排序最终构建的结构是一个散列表。 typedef int datatype;//numberLimits是数据区间的最大值,如果传入200,其区间就是[0, 200)int BucketSort(datatype *array, int size, int numberLimits){ int i, j; //temp是一个指针数组 Node **temp; Node *p, *s; if(array == NULL) { return -1; } //给指针数组temp分配空间 temp = (Node **)calloc(numberLimits / 10 + 1, sizeof(Node *)); if(temp == NULL) { return -1; } for(i = 0; i < size; i++) { p = temp[array[i] / 10]; //创建一个节点 s = (Node *)malloc(sizeof(Node)); if(s == NULL) { return -1; } s->data = array[i]; s->next = NULL; if(p == NULL)//如果最开始这个桶为空,则直接将这个结点存入 { temp[array[i] / 10] = s; } else { //如果桶不为空 //如果第一个结点的数据大于需要插入的数据 if(p->data > s->data) { s->next = p; temp[array[i] / 10] = s; } else { //在桶中查找需要查找的位置 while(p->next != NULL && p->next->data < s->data) p = p->next; s->next = p->next; p->next = s; } } } //根据这些桶重新给数组赋值,最终的结果就是一个有序的序列 for(i = 0, j = 0; i < numberLimits / 10 + 1; i++) { p = temp[i]; while(p) { array[j++] = p->data; p = p->next; } } return 0;}
你可能感兴趣的文章
利用Android Lost通过互联网或短信远程控制安卓设备
查看>>
用JvisualVM监视远程tomcat
查看>>
python基础 - 文件读写
查看>>
成大事必备9种能力、9种手段、9种心态
查看>>
php 依赖注入容器
查看>>
matlab设定mex接驳的C/C++编译器
查看>>
Linux系统备份与恢复
查看>>
机场打车有感
查看>>
利用数组创建的顺序表实现各种功能
查看>>
POJ - 1062 昂贵的聘礼(最短路Dijkstra)
查看>>
tomcat运行模式APR安装
查看>>
【菜鸟也疯狂UML系列】——概述
查看>>
Oracle成长点点滴滴(2)— 权限管理
查看>>
文件包含漏洞检测工具fimap
查看>>
详细解说 STL 排序(Sort)(转)
查看>>
Maven单独构建多模块项目中的单个模块
查看>>
Xamarin Essentials教程剪贴板Clipboard
查看>>
malloc()函数(Linux程序员手册)及函数的正确使用【转】
查看>>
MFC限制edit控件的字符输入长度
查看>>
url rewrite优化url的可读性
查看>>